Introduction
Here is a not so short note (Rolling Update) for machine learning and artificial intelligience. Main concepts and some references are presented. This note is based on Wikipedia, Andrew Ng’s Lecture Notes CS229 of Standford, Machine Learning course of SJTU IEEE-yangyang, and Machine Learning Crash Course of Google.
Bayesian estimation
If you flip a coin, what’s the probability it will fall with the head up? To solve this problem, you may flip the coin many times. You will get the data:
where means Head and means Tail. The probabilityshould be:
If you flip the coin 100 times, with 57 heads and 43 tails, the probability of should be 57/100. Because the flips are i.i.d., which means:
- Independent events
- Identically distributed according to Bernoulli distribution ( means BErnoulli distribution)
Maximum likelihood estimation
The aim of the maximum likelihood estimation is to choose that maximizes the probability of observed data. MLE of probability of head can be calculated based on i.i.d. as below:
Let . It is easy to find the that maximizes the probability of observed data:
Thus the MLE of probability of head is:
Prior and posterior
If you flip a coin 5 times, it is possible that 5 heads are obtained. In this case, the probability of head will be 1.0 if you use the maximum likelihood estimation. However, it is crazy to consider that the result of fliping a coin is always head. Thus, we need to use prior probability to adjust the probability calculation.
A prior probability distribution of an uncertain quantity is the probability distribution that would express one’s beliefs about this quantity before some evidence is taken into account. A prior can be determined from past information such as previous experiments, or according to some principle such as Jeffreys prior.
A posterior probability distribution of an unknow quantity is the probability distribution treated as the conditional probability that is assigned after the relevant evidence or background is taken into account. In contrasts with the likelihood function , the posterior probability is given as:
where is probability density function (pdf) of the prior probability.
Conjugate prior
In Bayesian probability theory, if the posterior distributions are in the same probability distribution family as the prior probability distribution , the prior and posterior are then called conjugate distributions, and the prior is called a conjugate prior for the likelihood function. When a family of conjugate priors exists, choosing a prior from that family simplifies posterior form.
An example of the conjugate prior: In the problem of coin flipping,
- Likelihood is ~ binomial distribution:
It means in independent flipping trial, the probability of occurring heads belongs to binomial distribution, with the probability of head is for every flipping.
- Prior is assumed as Beta distribution:
where , is the gamma function as an extension of the factorial function, , and , if is a positive integer.
- Posterior is also Beta distribution:
For binomial distribution, the conjugate prior is Beta distribution. The pdf of Beta distribution got more concentrated as values of and increased. As more samples are obtained, , the effect of prior will be “washed out”.
Another example of the conjugate prior: In the problem of rolling a dice, there are outcomes.
- Likelihood is ~ multinomial ()
The multinomial distribution is a generalization of the binomial distribution. In independent rolling test, the probability of occurring times of the dice number belongs to multinomial distribution, with the probability of is for every rolling. The sum of is 1 and the sum of is .
- Prior is assumed as Dirichlet distribution:
- Posterior is also Dirichlet distribution:
For multinomial, the conjugate prior is Dirichlet distribution.
MLE compared with MAP: maximum a posterior estimation
- MLE: to choose that maximizes the likelihood probability (the probability of observed data) P(X \mid \theta).
- MAP: to choose that maximizes the posterior probability P(\theta \mid X).
In the problem of flipping trial, the maximum a posterior estimation of probability of head is Beta distribution:
MLE vs MAP:
For small sample size, the prior is important. For infinite , prior will be useless. Therefore, when , MAP will be same as MLE.
We use Gaussian distribution for a continuous variable which is i.i.d. The central limit theorem (CLT) establishes that, in most situations, when independent random variables are added, their properly normalized sum tends toward a normal distribution
The pdf is :
where is the mean and is the variance.
MLE probability for Gaussian distribution:
MLE for Gaussian mean and variance:
Here we use average value to estimate , which is not a true parameter. The estimation of is under-estimated thus MLE for the variance of a Gaussian is biased. Because the average of is used as , the true mean is not equal to the average of samples. If we use the average of samples to estimate the average of total, there will be a bias. For a unbiased variance estimator:
Because only is independent with the average of samples. The can be obtained by the average and other values, which includes no additional information.
If we use different samples, the mean is also different. The prior for mean is also Gaussian distribution:
The conjugate prior for mean is Gaussian distribution and for variance is Wishart distribution.
Bayes classifier
Bayes Optimal Classifier
Bayes optimal classifier is a kind of ensemble learning. In Bayesian learning, the primary question is: What is the most probable hypothesis give data? If we have:
- X: Features
- Y: Target classes
How to decide which class is for a new sample with feature ? ( and )
The Bayes rule is:
According to the Bayes decision rule, we need to minimize the conditional risk of making a wrong classification of a sample. Becasue , the Bayes optimal classifier can be written as:
As the denominator is fixed for call cases, the maximum can be derived as:
- is the class conditional density (likelihood)
- is the class prior
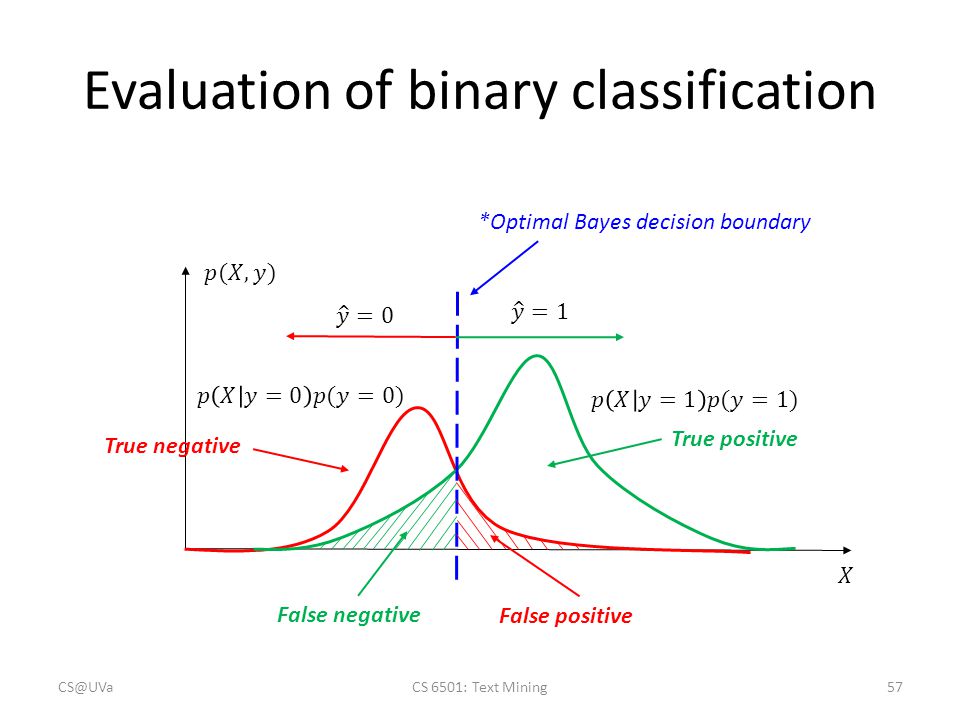
A binary classification and the optimal Bayes decision boundary is shown as follows.
Conditional independence
Given Z, X is conditionally independent of Y means:
e.g. If the alarm in your house is active (Z), your neighbor Mary will call the police (X) or another neighbor John will call the police (Y). It is assumed that they do not communicate for each other. In this case, Mary’s calling and John’s calling are conditionally independent. It also means whether Mary’s calling the police is irrelated to John’s calling:
Note: Independence Conditionally Independence
X is conditionally independent of Y with a given Z, does not mean that, X is independent of Y. e.g. It is unknown whether Mary’s calling is independent of John’s calling. They can call the police for other cases other than the alarm in your house. On the contrary, X is independent of Y, does not result to, X is conditionally independent of Y with a given Z. e.g.
- X: rolling a dice, the number is 3.
- Y: rolling a dice, the number is 2.
- Z: rolling a dice two times, the sum of the two numbers is 5.
In this case, X is not conditionally independent of Y with the given Z.
Naive Bayes (NB)
Naive Bayes Optimal Classifier assumes that the data is conditionally independent on the given class, which makes the computation more feasible.
where is the number of features. For each discrete feature, the likelihood is . If the class prior is $P(Y), the decision rule of Naive Bayes can be:
Actually, the features are not conditionally independent, then
Nonetheless, Naive Bayes sometimes still performs well even when the assumption of conditionally independence is violated. If the training data is insufficient, e.g., there is no sample for a feature in the class , the likelihood will be zero. No matter what the values take, the probability keeps zero as:
If the features are continuous, we use Gaussian Naive Bayes (GNB) instead. Let and . The probability is:
The subscript indicates the mean and variance for each class and each feature are different.
Reference
[1] Some common probability distributions
[2] Why use for unbiased variance estimation
[3] Example of NB: Sex classification based on features including height, weight, and foot size
